Building VibeCheckAI: A Social Media Sentiment Analysis Platform
Fri Sep 26 2025
Creating a scalable, production-ready sentiment analysis platform presents unique challenges when you are one person with a small personal budget! After doing some sentiment analysis on my own Threads post that went viral, I was inspired to build a tool to let content creators find trends in their viewers' feedback. It is privacy minded: the tool does not store any data for over 24 hours as of this writing. I also try to make it clear in the interface where their feedback is collected to train the models. This post seeks to take you through the process thusfar, and tell you a bit about where it's headed.
Project Overview
VibeCheckAI is currently a web application that analyzes YouTube video and channel comments using machine learning and artificial intelligence. I plan to expand to a number of social media platforms, but because of the ease of use of Google APIs and the high volume of YouTube comments, I started with YouTube. The platform currently processes up to 5,000 comments through a queuing mechanism available to premium users. Anyone can load up to 500 comments off of a video for analysis on the spot. It provides real-time sentiment analysis, theme detection, and some unique views of comment data for content creators.
Live Application: vibecheckai.pro
Main Repository: sentiment_analyzer
ML Service: sentiment_ml_service
Architecture & Technology Stack
Core Infrastructure
The application follows a microservices architecture with separation of concerns:
Web Application (Flask)
- Framework: Flask with blueprints for modular organization
- Database: PostgreSQL with SQLAlchemy ORM
- Caching: Redis for session management and job queuing
- Task Processing: Redis Queue (RQ) for asynchronous operations
- Authentication: Google OAuth 2.0 (to be expanded to other providers)
- Payments: Stripe API integration for subscription management
ML Service (Modal)
- Platform: Modal cloud with GPU acceleration
- Models: Transformer-based sentiment analysis (RoBERTa architecture)
- OpenAPI Integration: Uses OpenAI API for heavy language generation
- Deployment: Serverless GPU inference with automatic scaling
Frontend Technology
- UI Framework: Bootstrap 5 with custom CSS (though will be moving to another framework)
- JavaScript: Modern ES6+ with Vite-bundled React components
- Visualizations: Chart.js for interactive charts and custom canvas-based word clouds
Deployment Infrastructure
Production Environment (Railway)
- Web Service: Main Flask application with health checks
- Worker Service: Background job processor for comment analysis
- PostgreSQL: Primary database with automated backups
- Redis: Cache and job queue with persistence
- CI/CD: Automated deployment from GitHub with zero-downtime deployments
Key Technical Challenges & Solutions
1. Scalable Comment Processing
Challenge: Processing thousands of YouTube comments efficiently while maintaining real-time user feedback.
Solution: Implemented an asynchronous job queue system using Redis Queue (RQ):
# analysis_worker.py - Background job processor
from app.services.sentiment_api_service import SentimentAPIService
from app.services.youtube_service import YouTubeService
@job('default', timeout='30m')
def analyze_comments_async(video_id, analysis_id, user_limits):
# Fetch comments with pagination
comments = youtube_service.fetch_comments(video_id, limit=user_limits['max_comments'])
# Batch process for ML service efficiency
batched_comments = batch_comments(comments, batch_size=100)
for batch in batched_comments:
sentiment_results = sentiment_api_service.analyze_batch(batch)
# Update progress in Redis for real-time feedback
update_analysis_progress(analysis_id, len(processed))
Key Benefits:
- Non-blocking user experience with real-time progress updates
- Scaling through multiple worker processes
- Better handling of API rate limits and timeouts
2. ML Service Architecture
Challenge: Deploying transformer models cost-effectively with GPU acceleration while maintaining relatively low latency.
Solution: Leveraged Modal's serverless GPU infrastructure for the machine learning service:
Advantages of Modal:
- Automatic scaling based on demand
- GPU resource sharing across requests
- Cost efficiency through pay-per-use billing
The ML service exposes a couple simple RESTful API endpoints for batch sentiment analysis, enabling the main application to remain stateless while leveraging GPU acceleration for suitable ML tasks.
3. Real-time Progress Tracking
Challenge: Providing users with meaningful progress feedback during long-running analysis jobs.
Solution: Implemented WebSocket-like functionality using Redis and polling:
// Frontend progress polling
async function pollAnalysisProgress(jobId) {
const response = await fetch(`/analysis/status/${jobId}`);
const data = await response.json();
updateProgressBar(data.progress);
updateStatusMessage(data.message);
if (data.status === 'complete') {
window.location.href = `/analysis/results/${jobId}`;
} else if (data.status === 'failed') {
showErrorMessage(data.error);
} else {
setTimeout(() => pollAnalysisProgress(jobId), 2000);
}
}
Playful animations and rotating fun facts also keep the user engaged while the back end is doing quite a lot of processing.
4. YouTube API Integration & Rate Limiting
Challenge: Extracting comments while respecting YouTube's API quotas and providing intelligent caching to prevent more long-running queries and analysis when unnecessary.
Solution: Comprehensive YouTube service with intelligent Redis caching:
class YouTubeService:
def __init__(self):
self.api_client = build('youtube', 'v3', developerKey=API_KEY)
self.cache = Redis()
...
def fetch_comments(self, video_id, limit=1000):
cache_key = f"comments:{video_id}:{limit}"
cached = self.cache.get(cache_key)
if cached:
return json.loads(cached)
# Paginated comment fetching with error handling
comments = self._fetch_paginated_comments(video_id, limit)
self.cache.setex(cache_key, 86400, json.dumps(comments)) # 24h cache
return comments
Optimizations:
- 24-hour Redis caching for video metadata and comments
- Pagination to minimize API calls
- Graceful degradation when API limits are reached
5. User Authentication & Subscription Management
Challenge: Implementing secure authentication with flexible subscription tiers.
Solution: Google OAuth integration with Stripe for seamless user experience:
Authentication Flow:
- Google OAuth 2.0 for secure, passwordless authentication
- User profile creation with advanced queueing features and comment query limits
- Session management with secure cookie handling
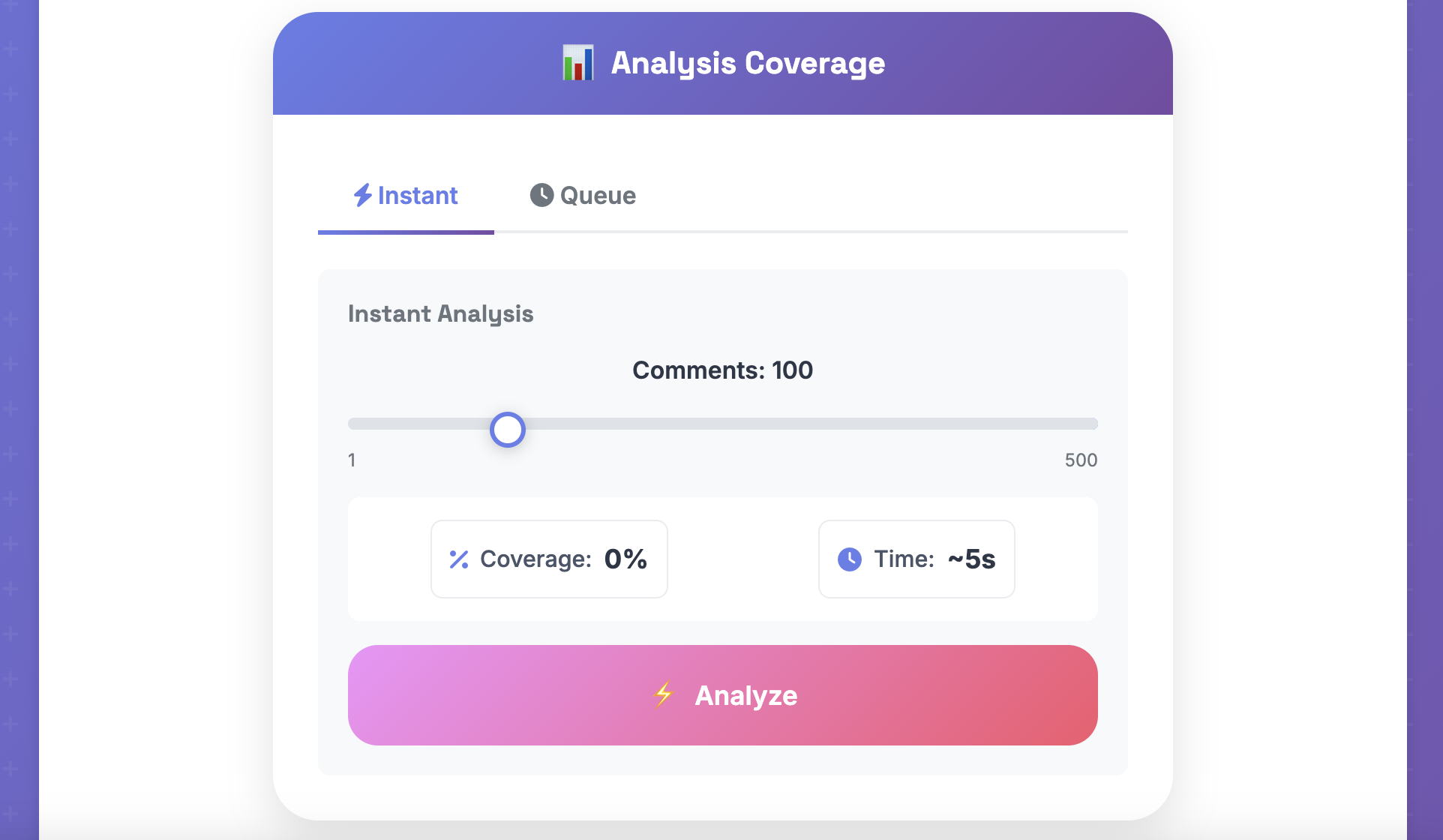
Subscription Job Queue Tiers:
- Free: 1,000 comments per analysis
- Logged-in: 2,500 comments per analysis
- Pro: 5,000 comments per analysis
6. Accurate Data Analysis
Challenge: Implementing an analysis method based on past research on social media sentiment analysis
Solution: An ensemble method of traditional machine learning algorithms and natural language processing models:
- Balances output of machine learning models with analysis from Meta's RoBERTa transformer model
- Uses OpenAI's GPT5 for robust English language summaries of datasets
- Manual tagging of a growing set of comments to train the models on and imrprove accuracy
Data Visualization & UI
Interactive Charts & Analytics
The frontend leverages Chart.js for responsive, interactive visualizations:
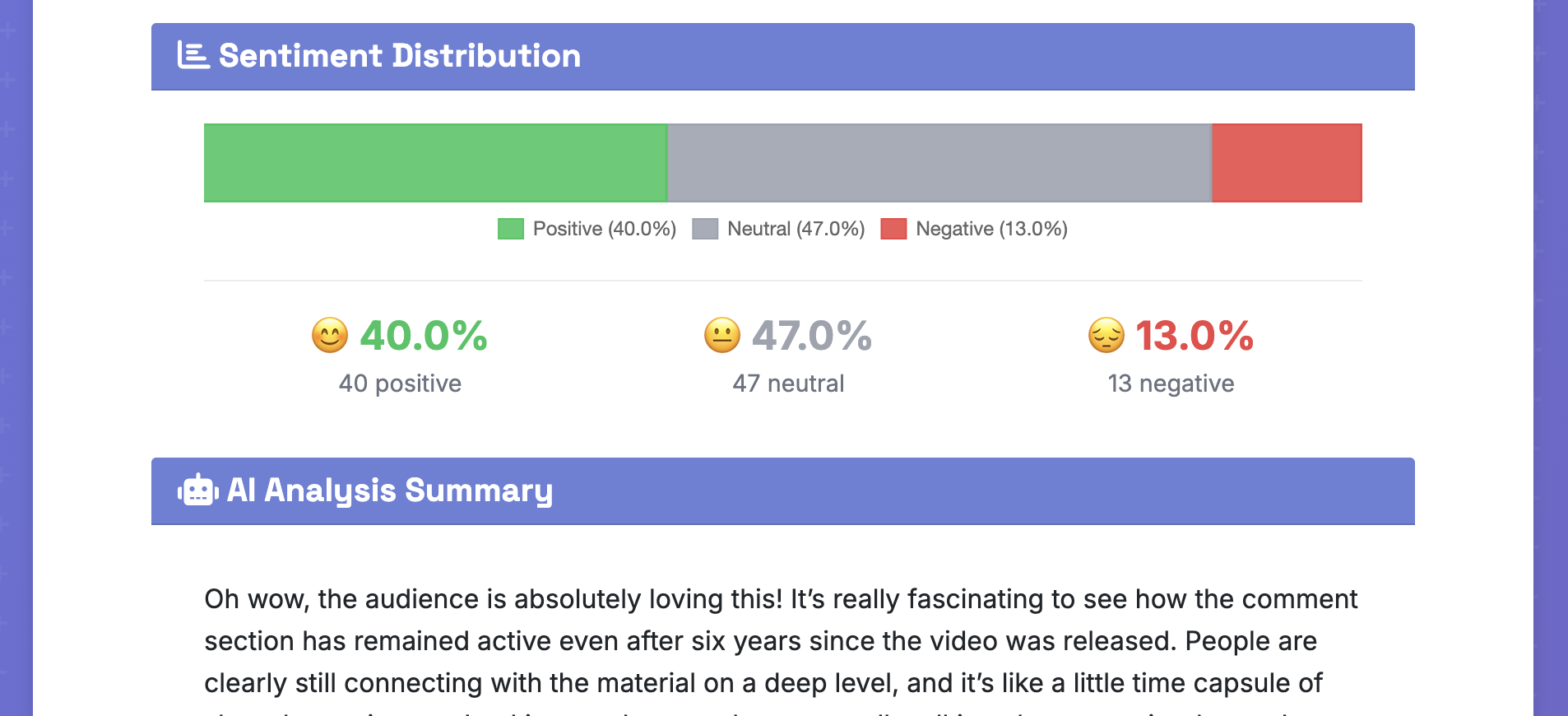
- Sentiment Distribution: Charts showing positive/negative/neutral percentages
- Confidence Scoring: Bar charts displaying model confidence levels
- Word Clouds: Canvas-based, interactive rendering of common words
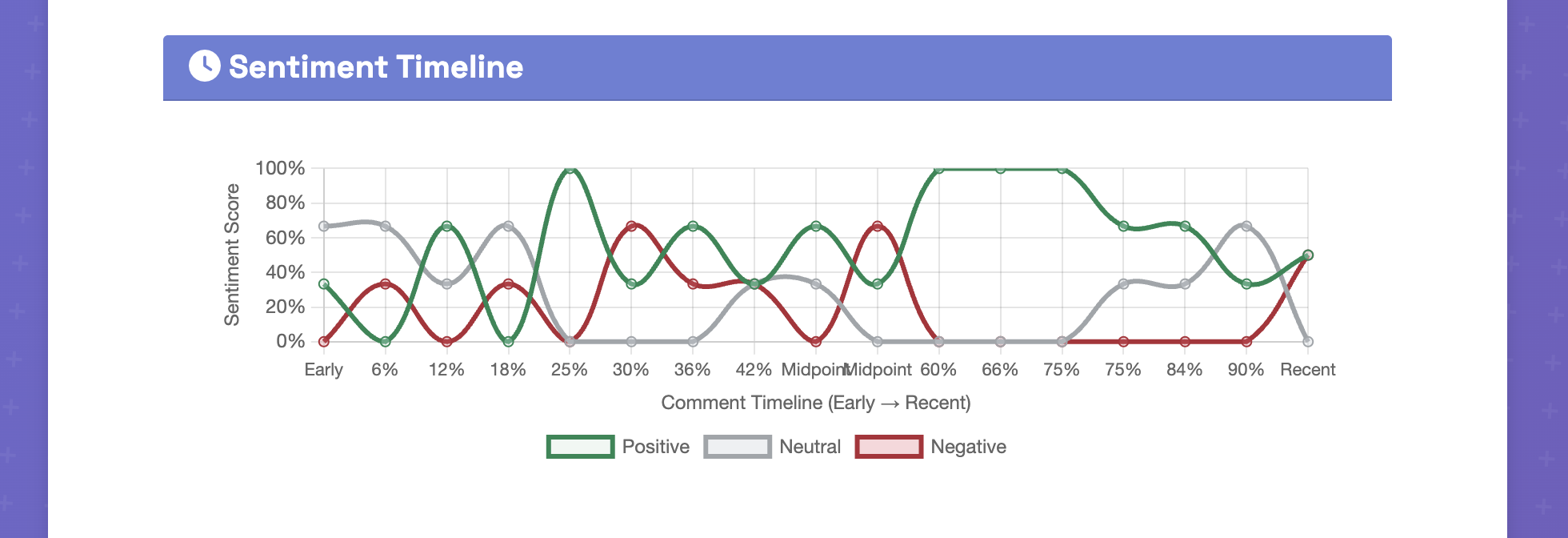
- Time-based Analysis: Line charts showing sentiment trends over time
React Component Integration
Before launch, I moved from a semi-fragile vanilla JavaScript strategy to a modern React front end. Components are integrated within the Flask templates using Vite bundling:
// Vite-bundled React component for dynamic interactions
import { useState, useEffect } from 'react';
export default function AnalysisResults({ analysisId }) {
const [results, setResults] = useState(null);
const [loading, setLoading] = useState(true);
useEffect(() => {
fetchAnalysisResults(analysisId)
.then(setResults)
.finally(() => setLoading(false));
}, [analysisId]);
return (
<div className="analysis-container">
{loading ? <LoadingSpinner /> : <ResultsDisplay data={results} />}
</div>
);
}
Performance Optimizations
Multi-level Caching Strategy
Redis Caching:
- YouTube API responses (24-hour TTL)
- User session data
- Job queue state and progress
Database Optimizations:
- Indexed queries for user analysis history
- Pagination for large result sets
- Connection pooling with SQLAlchemy
Frontend Performance:
- Lazy loading of visualizations
- Progressive enhancement with React components
- Asset bundling with Vite
Scaling Considerations
Horizontal Scaling:
- Stateless web application design
- Multiple Redis Queue workers
- Scalable web instances with Railway
Resource Optimization:
- GPU sharing through Modal's serverless architecture
- Batch processing machine learning inferences
- Background processing for non-critical operations
Security & Reliability
Security Measures
- CSRF Protection: All forms protected against cross-site request forgery
- SQL Injection Prevention: Parameterized queries via SQLAlchemy ORM
- XSS Prevention: Template auto-escaping and input validation
- Secure Sessions: HTTPOnly cookies with Redis backing
- Rate Limiting: API endpoint protection against abuse
Security is a top priority for me, and I've taken steps to ensure that the application is secure and reliable. I learned a lot in this process, and am using industry-standard tools and practices.
Monitoring & Health Checks
- Application Health: Endpoint monitoring for uptime tracking
- Error Tracking: Comprehensive logging with error aggregation
Testing & Quality Assurance
Comprehensive Test Suite
The project aims to maintain 85%+ test coverage with pytest:
# Example test structure
class TestSentimentAPIService:
def test_batch_analysis_success(self, mock_requests):
mock_requests.post.return_value.json.return_value = {
'results': [{'sentiment': 'positive', 'confidence': 0.95}]
}
service = SentimentAPIService()
results = service.analyze_batch(['Great video!'])
assert len(results) == 1
assert results[0]['sentiment'] == 'positive'
Testing Categories:
- Unit tests for service layer logic
- Integration tests for database operations
- API endpoint testing with mocked external services
- Frontend component testing with Jest
Deployment & DevOps
Railway Deployment Pipeline
Railway provides automated CI/CD with the following services:
{
"build": {
"command": "npm run build && pip install -r requirements.txt"
},
"deploy": {
"startCommand": "python run.py",
"healthcheckPath": "/health"
}
}
Deployment Features:
- Zero-downtime deployments with health checks
- Automatic rollback on deployment failures
- Database migrations with Flask-Migrate
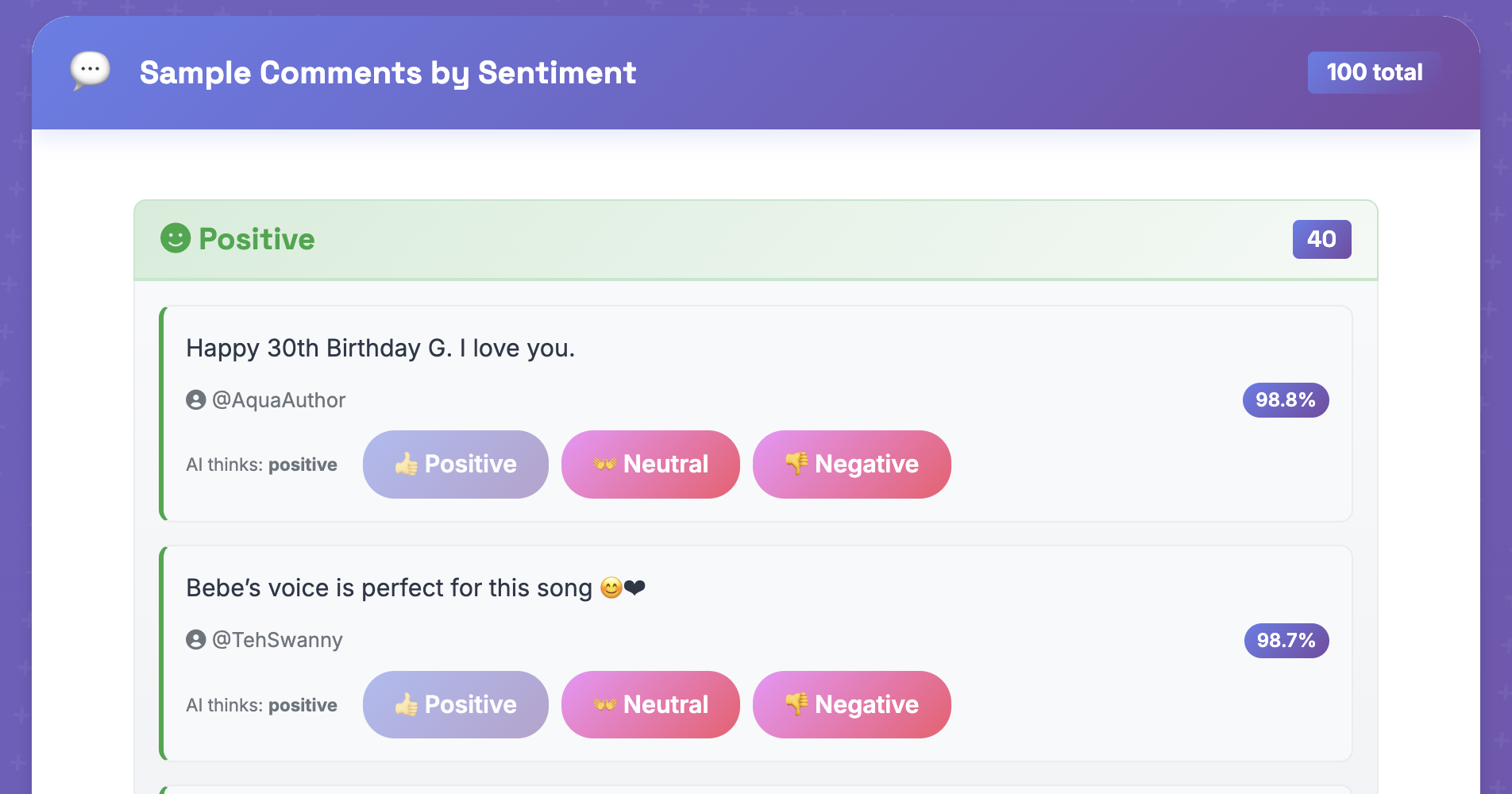
Lessons Learned & Future Enhancements
Key Takeaways
- Microservices Benefits: Separating ML inference into a dedicated service improved scalability and cost efficiency, while increasing processing power exponentially
- Async Processing: Redis Queue enabled responsive user experience for long-running operations
- Caching Strategy: Multi-level caching significantly improved performance, this project feels like all caching and workers!
- Modern Frontend: React component integration provided dynamic interactions while maintaining SEO benefits by leveraging server-side templating where most beneficial for performance and findability.
Planned Improvements
Technical Enhancements:
- Additional data visualization for premium users
- Integrating with other social media platforms
- Refactoring out old branches of code, legacy code left from speeding through development
- Implement solutions for faster processing times, especially on larger datasets
- Model training and fine-tuning in-flight, so to speak
- I would like to get the models to infer sarcasm to some degree
- Tokenizing emoji and preserving weighing emphasis in comments
Infrastructure Scaling and Improvements:
- Auto-scaling of web and database instances w/ load balancing
- Database read replicas for quick access of data
- Enhanced monitoring of errors in logs and a bug remediation practice
Conclusion
Building VibeCheckAI required balancing modern web development practices with the unique challenges of ML-powered applications. The microservices architecture with Flask and Modal enabled rapid development while achieving a slow rollout, but production-grade reliability and performance. I spent the better part of a month creating and perfecting this tool, with the aid of AI.
I learned so much about infrastructure, more than even about the machine learning/artificial intelligence pieces so far. I'm really excited to keep it growing, under this hopefully comprehensive suite of automated tests.
The data analysis results are not what I'd want always, but with increased hyperparameter tuning, more training data, implementing some social media-enhanced features like emoji tokenization and perhaps a social media-tuned instance of the RoBERTa model, which was shown to do quite well in my initial experiments.
Thanks so much for reading, please go and play with the tool if you haven't. There's so much more I could say but I'd like you to experience it! Please do let me know if you encounter any bugs! Thank you! https://vibecheckai.pro
Comments
No comments yet. Be the first!